



Prompt Engineering That Turns LLMs Into Reliable Production Systems
Vervelo designs, evaluates, versions, and manages prompts as production software artifacts — with structured frameworks, measurable quality gates, and context architectures built for real-world AI.


Why Teams Choose Vervelo for Prompt Engineering
Most prompt engineering is ad hoc — strings written in notebooks, iterated by feel, never formally evaluated. Vervelo brings software engineering discipline to prompts: version control, evaluation harnesses, A/B testing, and production monitoring so your AI system's behavior is predictable, measurable, and improvable over time.

3x
Faster Prompt Iteration
Structured evaluation pipelines reduce prompt iteration cycles compared to manual testing
40%
Reduction in Token Costs
Average inference cost reduction through optimized prompt structure and context window budgeting
95%
Output Consistency Rate
Achieved through structured system prompts, output schemas, and regression test suites
100%
Version-Controlled Prompts
Every prompt treated as a production artifact with full lineage, rollback, and changelog
Prompt Engineering Service Areas
4 Prompt Engineering Disciplines — One Integrated Practice
From problem definition and prompt development through evaluation, context architecture, and production management — every layer of the prompt engineering stack, handled as a professional engineering discipline.
Service 01
Problem Definition & Prompt Development
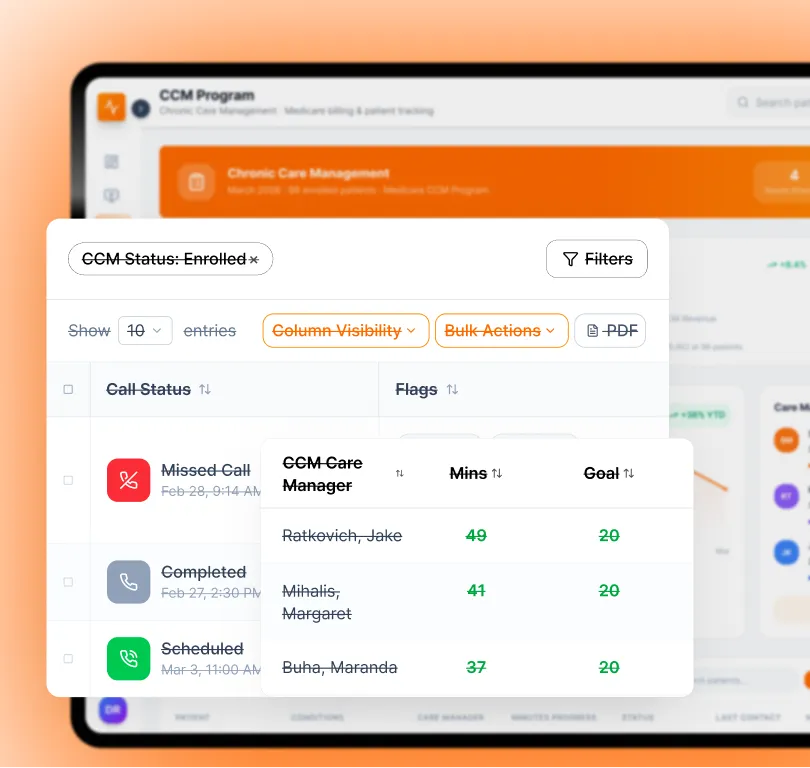
Use case scoping, input/output contract definition, structured prompt design using chain-of-thought, few-shot, and zero-shot techniques, and healthcare-specific prompt patterns for clinical AI applications.
Service 02
Prompt Evaluation & Iterative Optimization
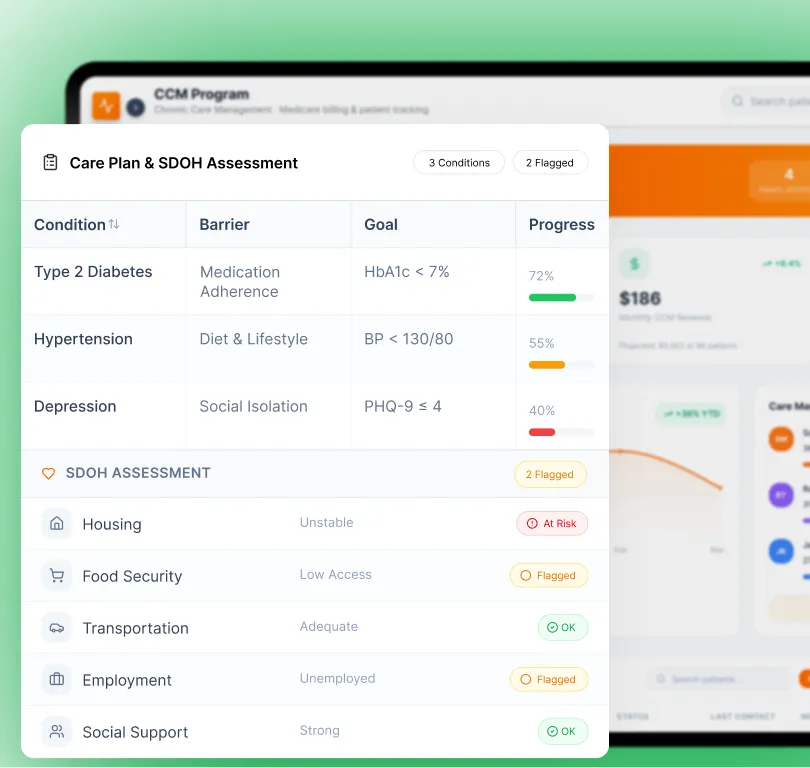
Ground truth dataset construction, automated metrics (ROUGE, BERTScore, RAGAS, LLM-as-judge), human-in-the-loop review panels, and systematic A/B prompt comparison with statistical significance testing.
Service 03
Context Architecture & Memory Design
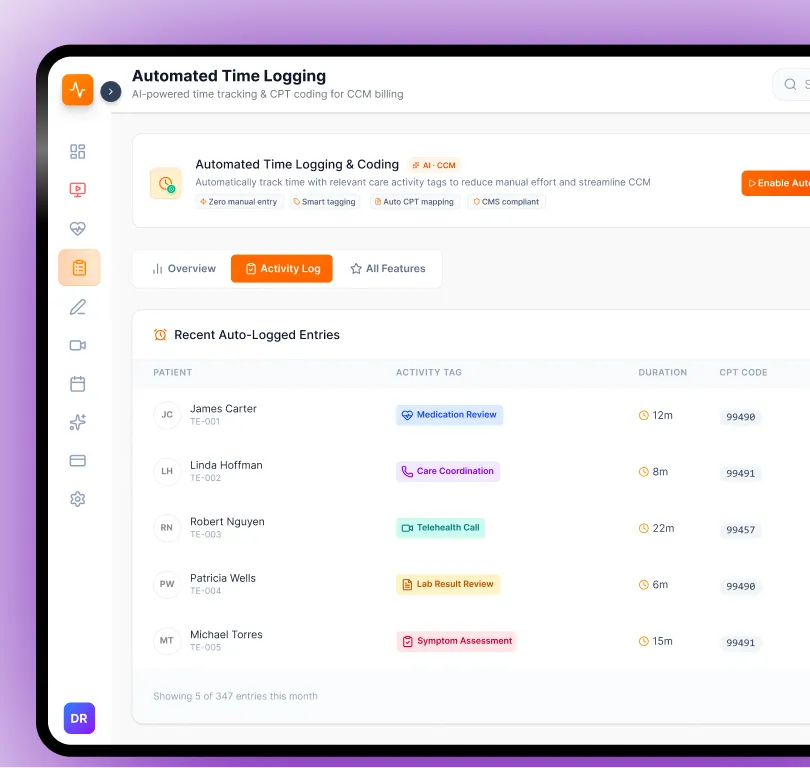
Context window budget strategy, session memory and conversation state design, and retrieval-to-prompt pipeline architecture for RAG systems that need the right knowledge in the right format.
Service 04
Production Prompt Management
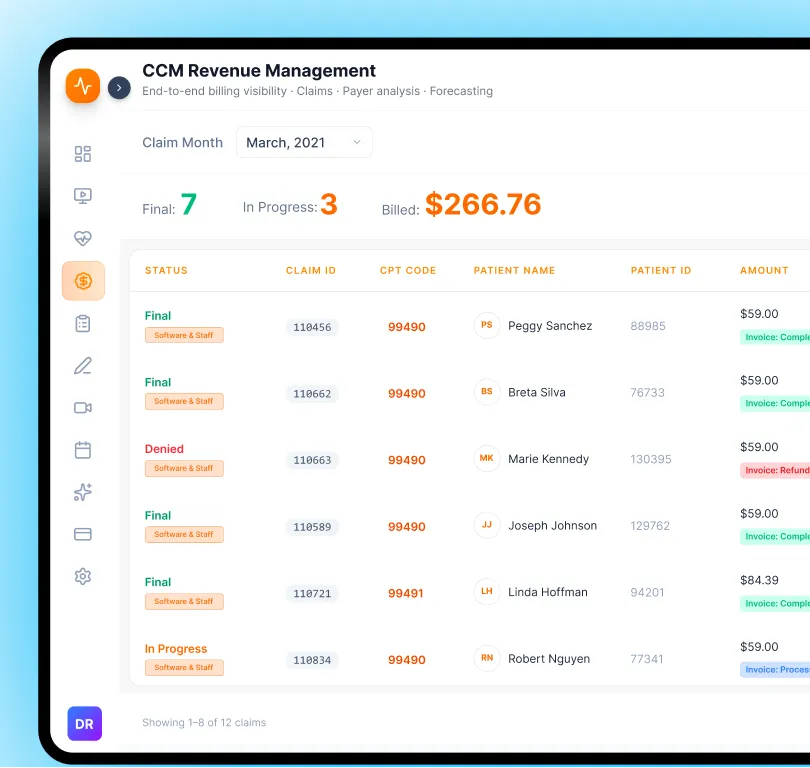
Prompt versioning and registry, regression testing in CI/CD pipelines, and production monitoring with drift detection and clinical safety alerting for healthcare AI deployments.
Supporting Capabilities
Technologies & Practices Built Into Every Prompt Engineering Engagement
LLM-as-Judge Evaluation
Automated quality scoring using a stronger LLM to evaluate outputs from the production model — assessing correctness, completeness, tone, and format compliance at scale without requiring human review for every test case.
Multi-Model Prompt Portability
Prompt designs tested and validated across multiple model families (GPT-4o, Claude, Gemini, Llama, Mistral) to ensure your AI system is not locked to a single provider and can be migrated or multi-homed as model capabilities evolve.
Structured Output Enforcement
JSON schema binding, function calling, and output parser implementation that enforce the exact output structure your downstream systems expect — eliminating the brittle string-parsing that causes most LLM integration failures.
Adversarial Prompt Testing
Red-teaming exercises against your prompt system to identify injection vulnerabilities, jailbreak exposure, and edge-case failures — with structured hardening recommendations and guardrail design to close identified gaps.
Few-Shot Example Curation
Systematic selection, diversity analysis, and quality control of few-shot examples — ensuring demonstrations represent the full input distribution, avoid bias introduction, and are updated as the ground truth evolves.
Prompt Cost Optimization
Token usage analysis, context compression techniques, prompt shortening without quality loss, and caching strategies (semantic caching, prefix caching) that reduce inference costs without degrading output quality.
Why Build Your Prompt Engineering Practice with Vervelo
Most teams treat prompt engineering as an informal skill. Vervelo treats it as a software engineering discipline — with the tooling, processes, and measurement frameworks that separate production-grade AI from weekend prototypes.
Engineering-Grade Discipline
Prompts are version-controlled, evaluated against ground truth datasets, regression-tested in CI/CD, and monitored in production. Not ad hoc strings iterated by feel.
Healthcare AI Depth
Clinical prompt patterns, HIPAA-compliant evaluation workflows, and safety guardrails designed for the risk profile of healthcare AI applications. We understand the clinical domain, not just the LLM API.
Model-Agnostic Approach
Prompt designs validated across OpenAI, Anthropic, Google, and open-source model families. Your prompts are not hostage to a single provider's pricing or terms.
Measurable Outcomes
Every engagement produces a quantified performance baseline, a structured evaluation dataset, and a version-controlled prompt library — so improvements are measurable and results are reproducible.
Our Process
How Vervelo Delivers Prompt Engineering Engagements
A structured, phase-driven process that moves from problem definition to production-grade prompt systems — without the ad hoc iteration and undocumented decisions that make most prompt engineering work impossible to maintain.
Use Case Definition & Scoping
We interrogate the use case — what problem are we solving, what does a correct output look like, what are the failure modes, and what constraints (latency, cost, safety) apply. We produce a use case brief with a defined input/output contract before any prompt work begins.
Ground Truth Dataset Construction
We build or validate the evaluation dataset — representative input examples, correct output labels, edge cases, and adversarial inputs. For healthcare use cases, this includes clinical SME review to ensure label correctness. The dataset defines what 'good' means for this application.
Baseline Prompt Development
We develop an initial set of prompt candidates using structured techniques appropriate to the task type and model. Each candidate is documented with the rationale for technique choices, the system prompt design, and the few-shot example selection strategy.
Evaluation & Iterative Optimization
Each prompt candidate is scored against the ground truth dataset using automated metrics and human review. We run A/B comparisons across candidates, temperature settings, and model versions — iterating until performance meets the defined quality thresholds.
Context Architecture & Integration
We design the context window budget strategy, session memory architecture, and retrieval context pipeline — then integrate the prompt system into your application with structured output parsing, error handling, and fallback logic.
Production Deployment & Monitoring
We deploy with a prompt registry, versioning infrastructure, and regression test suite in place. Post-launch monitoring tracks output quality, detects distribution shift, and alerts on safety violations — with a clear process for prompt updates that maintains the full evaluation chain.
Over 120+ custom healthcare solutions Built and developed to deliver excellent patient care, drive clinical innovation and meet regulatory compliance standards
Ready to engineer prompts that work in production?
Talk to Vervelo's prompt engineering team about your use case
Our expertise in healthcare
Healthcare software development success case studies

4x
faster RPM launch and deployment across 3 clinics
CarePlus TeleHealth
Built a custom remote-patient-monitoring (RPM) platform for a U.S. home-care provider, allowing them to deploy monitoring to 3 clinics in under 8 weeks — four times faster than their previous in-house attempts.
View case study
60%
staff-time savings on admin tasks
GrandView Hospital
A major hospital system with fragmented legacy systems engaged Vervelo to build an integrated EHR + billing + patient portal + telehealth platform.
View case study
5x
growth in patient engagement
HealthBridge
Health-tech startup offering subscription-based telehealth and chronic-care services partnered with Vervelo to build a user-friendly patient portal and mobile app.
View case study
Compliance-First Software that Protects your and your patients Data
We build healthcare AI with compliance and security built in from the start. Our team understands HIPAA, FDA guidance, ISO 27701, GDPR, SOC 2 and modern interoperability (HL7 FHIR). All prompt systems handling PHI are designed with data minimization, audit logging, and access control as standard requirements.



What Vervelo Brings to Healthcare AI
We've helped organisations from small clinics to large health systems improve AI reliability with structured prompt engineering, cut model inference costs by over 40 percent, and build production AI systems that maintain quality over time without constant manual intervention.
Engineering + Healthcare Domain Expertise
We combine strong healthcare domain knowledge with expert prompt engineering to build reliable clinical AI. You get fast delivery, full ownership of your prompt library, and AI that works the way your clinical workflows actually require.
Healthcare-First AI Development
We follow proven healthcare AI development practices that create secure, reliable systems with measurable outcomes. Our approach reduces clinical risk, supports regulatory compliance, and helps you make confident AI deployment decisions.
Structured Evaluation & Measurable Quality
Every prompt system we build has a defined quality baseline and a structured evaluation framework. You always know how your AI is performing, what changed when quality shifted, and what to do about it.
Built with Compliance and Data Security
Patient privacy and regulatory compliance are non-negotiable in healthcare AI. We include HIPAA-ready data handling, PHI minimization in prompt context, audit logging, and safe output guardrails from the start of every engagement.
Vervelo is a digital-health software partner blending deep clinical insight with world-class engineering to build tailored, secure, interoperable healthcare platforms. With a team of HIPAA- and FHIR-trained professionals and a track record of delivering 120+ custom healthcare solutions, we help healthcare providers, startups, and health-tech companies accelerate innovation, improve patient care, and simplify operations.
-

Vervelo designs your AI prompt systems around your unique workflows and specialty — prompts that reflect how your team actually works, not how a generic LLM demo is configured.
-

Choose the prompt engineering services and evaluation depth that match your maturity and risk level. Nothing extra to slow things down.
-

Optimized prompts reduce inference token usage by 30–40% on average — lowering your AI infrastructure costs while improving output quality.

Frequently Asked
Questions
Have a question that needs a human to answer? No problem.
Speak to our team now →
What is prompt engineering and why does it matter for production AI?
Prompt engineering is the discipline of designing, evaluating, and managing the instructions given to a large language model to produce reliable, high-quality outputs. In production, the quality of your prompts directly determines the consistency and accuracy of your AI system. Without structured prompt engineering — version control, evaluation frameworks, regression testing — prompt changes are unpredictable and quality degradation goes undetected.
How is Vervelo's approach different from using an AI platform's built-in tools?
Platform playgrounds are for experimentation. Vervelo's prompt engineering practice is for production. We bring version control, ground truth evaluation datasets, automated regression testing, clinical SME review, and production monitoring — the full software engineering infrastructure that platform tools don't provide. We also design prompts to be model-portable, so you're not locked to one provider's API.
Do you work with healthcare-specific AI use cases?
Yes — healthcare AI is our primary domain. We have battle-tested prompt patterns for clinical note summarization, ICD/CPT code suggestion, prior authorization generation, care gap identification, patient communication, and clinical decision support. All healthcare prompt work is conducted under HIPAA-compliant data handling protocols with clinical SME review as standard.
Can you work with models we're already using?
Yes. We design and optimize prompts for GPT-4o, Claude, Gemini, Llama, Mistral, and other model families — both API-based and self-hosted. Our evaluation frameworks are model-agnostic, so we can benchmark your current model against alternatives and give you evidence-based recommendations if a model change would improve performance or reduce cost.