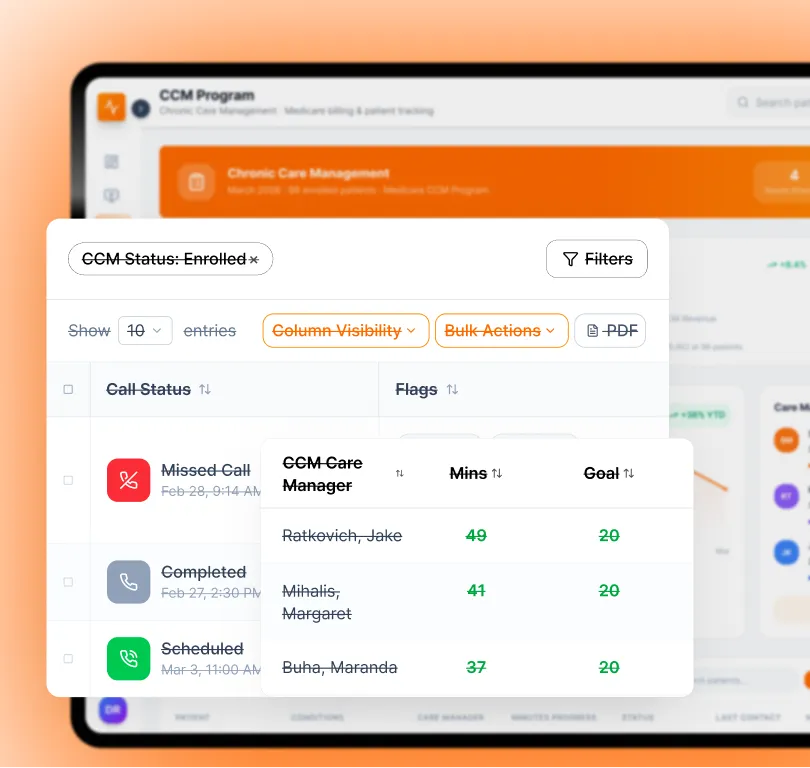
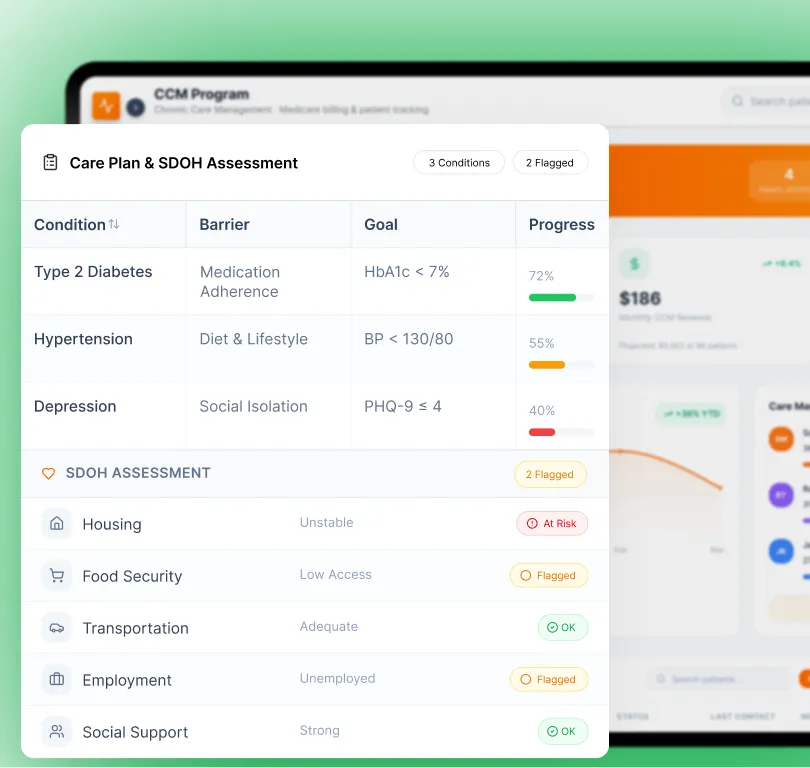
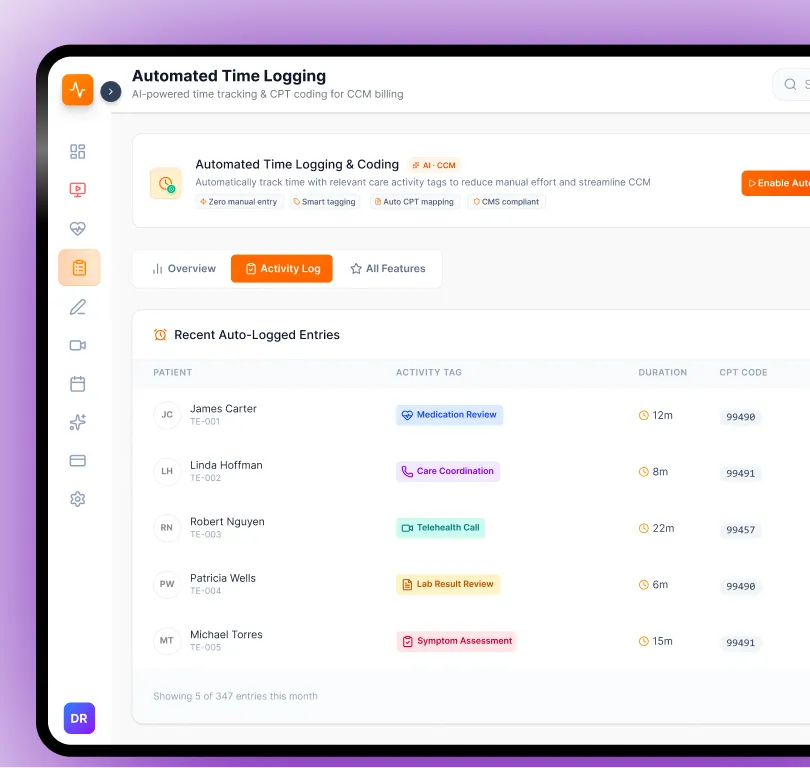
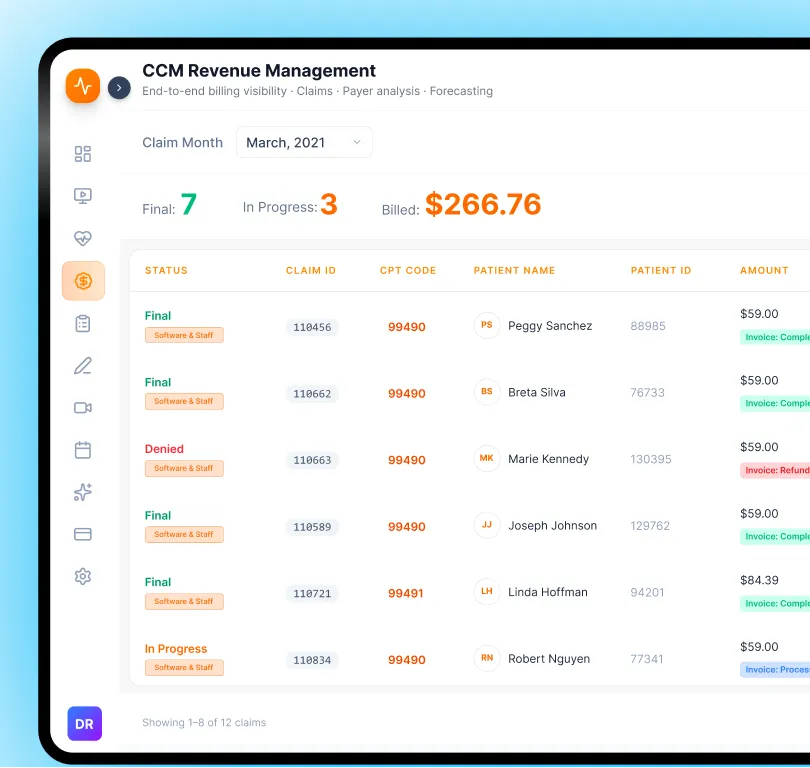
Capability 01
Data Strategy and Discovery
We define the right data strategy before collection starts. This includes use-case scoping, source mapping, schema alignment, and quality criteria tailored to your AI roadmap.
Core Activities
- Map AI use cases to required data domains and granularity
- Audit available data sources, formats, and ownership boundaries
- Define schema standards for structured and unstructured content
- Set quality, completeness, and freshness thresholds
Deliverables
- Data strategy blueprint
- Source inventory and gap analysis
- Governance and ownership model
Expected Outcomes
- Clear collection scope
- Reduced downstream rework