



Context Engineering Giving Your AI the Right Information at the Right Time
Vervelo engineers the full context stack — RAG pipelines, knowledge base architecture, memory systems, and context window strategies that ensure your AI always reasons from accurate, relevant, well-structured information.


Why Teams Choose Vervelo for Context Engineering
A well-prompted model with poor context will still hallucinate, drift, and produce outputs that cannot be trusted. Context engineering is the discipline that gives the model the right information at the right time — through retrieval pipelines, memory architectures, and context window strategies designed with the same rigor as production software. Vervelo builds these systems from the ground up, not as afterthoughts.

70%
Reduction in Hallucinations
Average hallucination rate reduction achieved through structured RAG pipelines and retrieval validation
3x
Retrieval Precision Improvement
Typical gain from optimized chunking, embedding selection, and hybrid retrieval over naive vector search
50%
Lower Inference Cost
Context window budget optimization reduces token usage while maintaining or improving output quality
<200ms
Retrieval Latency Target
Production retrieval pipelines engineered for sub-200ms end-to-end latency including reranking
Context Engineering Service Areas
4 Context Engineering Disciplines — One Integrated Practice
From knowledge base construction and retrieval pipeline design through memory architecture and context window management — every layer of the context stack, engineered for production reliability.
Service 01
RAG Pipeline Design & Implementation
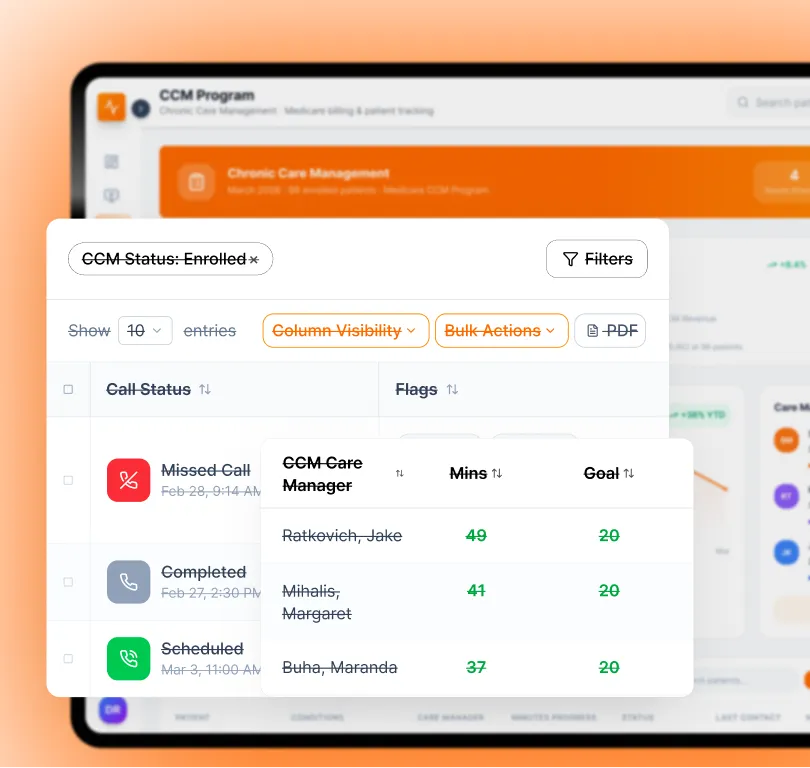
Document chunking strategy, embedding model selection and benchmarking, and hybrid retrieval with reranking — designed for your document types, query patterns, and production latency targets.
Service 02
Knowledge Base Architecture & Data Ingestion
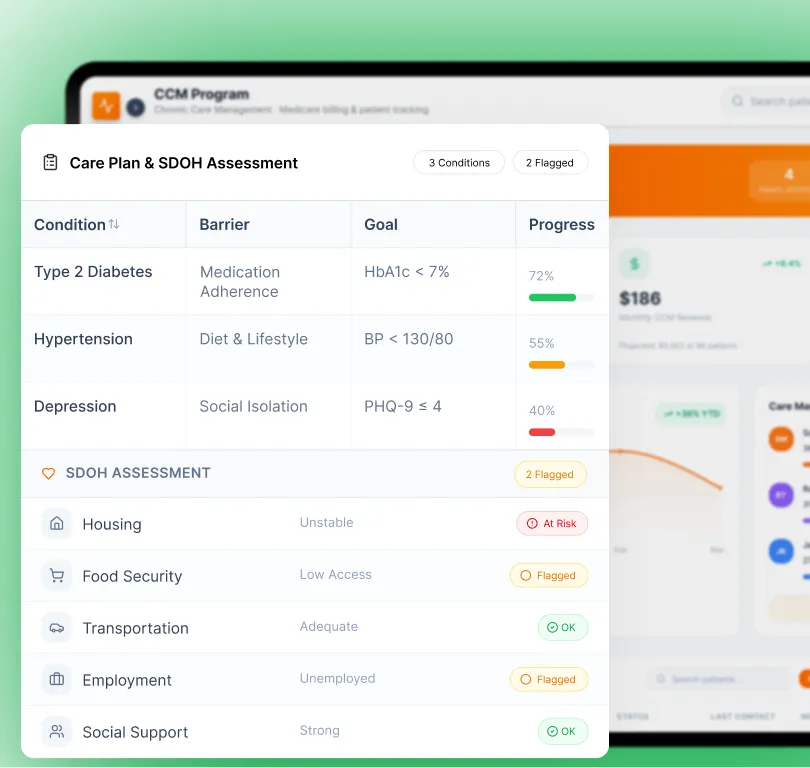
Multi-source ingestion pipelines for PDFs, EHR data, FHIR resources, and payer documents — with vector store selection, index design, metadata schema, and filtered retrieval for access control and temporal freshness.
Service 03
Memory Systems & Conversational State
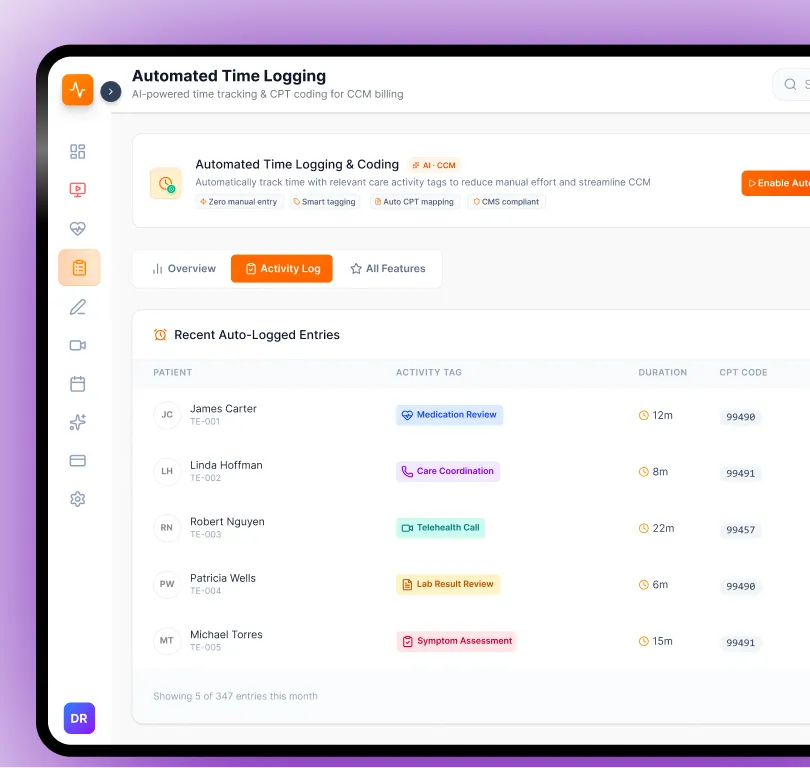
Session memory with sliding window and summarization compression, long-term patient and user memory with HIPAA-compliant storage, and semantic knowledge memory with knowledge graph and vector retrieval integration.
Service 04
Context Window Management & Optimization
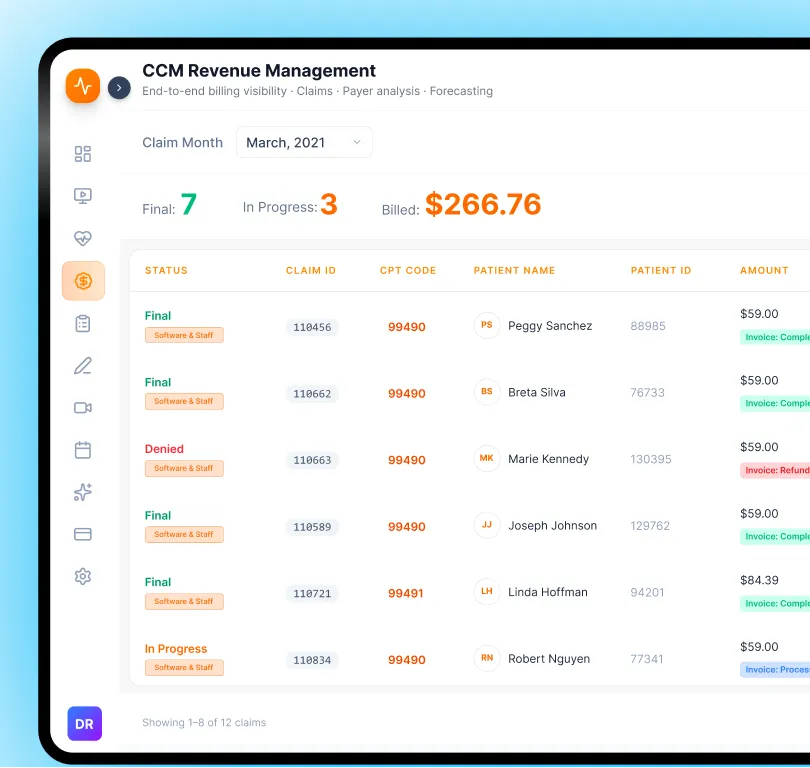
Context budget strategy to prevent lost-in-the-middle degradation, compression pipelines that preserve information fidelity, and caching architectures that hit production latency targets without quality tradeoffs.
Supporting Capabilities
Technologies Built Into Every Context Engineering Engagement
FHIR-Native Data Integration
Ingestion and normalization of HL7 FHIR resources (Patient, Observation, Condition, MedicationRequest, DocumentReference) into retrieval-ready formats — preserving clinical relationships and enabling structured filtering by patient, encounter, and clinical concept.
Knowledge Graph Construction
Extraction of entities and relationships from clinical documents to build structured knowledge graphs — enabling the model to traverse clinical concept hierarchies, drug-interaction networks, and care pathway relationships that flat vector retrieval cannot represent.
Retrieval Quality Evaluation
Systematic measurement of retrieval pipeline performance using RAGAS metrics (context precision, context recall, faithfulness, answer relevancy) against ground truth datasets — so retrieval quality is measured, not assumed.
Document-Level Access Control
Retrieval pipeline integration with your authorization system — ensuring users only retrieve documents they are permitted to access, with role-based and patient-specific access control enforced at the retrieval layer before content reaches the model.
Real-Time Data Integration
Context pipelines that pull live data — patient vitals from RPM devices, lab results from LIS systems, current medication lists from pharmacy systems — and inject it into the context window alongside static knowledge base content.
Multi-Modal Context Handling
Context pipelines that process and inject not just text but structured data, tables, clinical images (with vision model integration), and audio transcripts — enabling AI systems that reason across the full range of clinical information types.
Why Build Your Context Engineering Stack with Vervelo
Context engineering is the most underinvested layer in most GenAI projects. Vervelo brings production engineering discipline to retrieval, memory, and context management — the infrastructure that separates AI that works from AI that occasionally works.
Healthcare Context Depth
We understand the clinical information landscape — FHIR resources, EHR document types, clinical terminology, payer policy structures, and the access control requirements that govern PHI retrieval. General AI shops don't.
Retrieval-First Engineering
We benchmark retrieval quality before building the application layer. Context precision and recall are measured metrics in every engagement — not feelings about whether the system seems to work.
Production-Grade Architecture
Latency targets, caching strategies, index optimization, and monitoring are designed in from the start. Context pipelines are built to operate reliably at production request volumes, not just in demos.
Compliance by Design
PHI de-identification in ingestion pipelines, access control at the retrieval layer, audit logging of every context assembly, and HIPAA-aligned data handling throughout the knowledge base stack.
Our Process
How Vervelo Delivers Context Engineering Engagements
A structured delivery process that builds retrieval and context systems on measurable foundations — not intuition about what might work.
Knowledge Audit & Source Mapping
We inventory your knowledge sources — document types, volumes, update frequency, access control requirements, and PHI exposure. We map the information architecture the AI system needs to reason over before any pipeline is built.
Retrieval Baseline & Benchmarking
We construct a retrieval evaluation dataset of representative queries with ground truth relevant passages, then benchmark baseline retrieval approaches to establish the starting point. This surfaces where naive approaches fail before production commitment.
Chunking & Embedding Strategy
We design and test chunking strategies and embedding model candidates against the retrieval benchmark dataset — selecting the combination that maximizes context precision and recall for your specific document types and query patterns.
Pipeline Build & Integration
We build the full ingestion pipeline, vector store index, hybrid retrieval configuration, and reranking layer — integrated with your application, EHR system, or agent framework. Access control and PHI handling are built in at this stage.
Memory Architecture & Context Budget
We design the session memory, long-term memory, and context window budget strategy for your specific use case — with compression pipelines and caching layers tuned for your latency and cost targets.
Production Monitoring & Optimization
We deploy with retrieval quality monitoring in place — tracking context precision, recall, and faithfulness metrics on live traffic. Ongoing optimization adjusts chunking, retrieval parameters, and memory strategies as query patterns evolve.
Over 120+ custom healthcare solutions Built and developed to deliver excellent patient care, drive clinical innovation and meet regulatory compliance standards
Ready to eliminate hallucinations with production-grade context engineering?
Talk to Vervelo's context engineering team about your retrieval and memory requirements
Our expertise in healthcare
Healthcare software development success case studies

4x
faster RPM launch and deployment across 3 clinics
CarePlus TeleHealth
Built a custom remote-patient-monitoring (RPM) platform for a U.S. home-care provider, allowing them to deploy monitoring to 3 clinics in under 8 weeks — four times faster than their previous in-house attempts.
View case study
60%
staff-time savings on admin tasks
GrandView Hospital
A major hospital system with fragmented legacy systems engaged Vervelo to build an integrated EHR + billing + patient portal + telehealth platform.
View case study
5x
growth in patient engagement
HealthBridge
Health-tech startup offering subscription-based telehealth and chronic-care services partnered with Vervelo to build a user-friendly patient portal and mobile app.
View case study
Compliance-First Software that Protects your and your patients Data
Every context pipeline we build for healthcare handles PHI with HIPAA-aligned de-identification, access control, and audit logging. We understand HL7 FHIR, SOC 2, GDPR, and the data handling requirements that govern clinical AI — and we build them into the retrieval architecture from day one, not as compliance patches after the fact.



What Vervelo Brings to Healthcare AI
We've helped organisations from small clinics to large health systems eliminate AI hallucinations through structured context engineering, reduce retrieval latency to under 200ms in production, and build knowledge bases that stay accurate as clinical guidelines and payer policies evolve.
Clinical Information Architecture
We understand the structure of clinical knowledge — FHIR resource relationships, EHR document hierarchies, clinical coding systems, and payer policy organization. Context pipelines we build reflect the real structure of healthcare information, not a generic document store.
Retrieval Quality as a Measured Metric
We don't ship retrieval pipelines without measuring them. Every engagement produces a retrieval evaluation dataset and benchmark scores. You always know what your system's retrieval precision and recall are — and when they change.
EHR and FHIR Integration
We integrate context pipelines directly with major EHR systems and FHIR APIs — pulling real-time patient data, clinical notes, and structured observations into the context window with appropriate access control and PHI handling throughout.
PHI-Safe Retrieval by Design
Access control is enforced at the retrieval layer — users only see documents they are authorized to access, de-identification is applied at ingestion for non-clinical contexts, and every context assembly is audit-logged for compliance.
Vervelo is a digital-health software partner blending deep clinical insight with world-class engineering to build tailored, secure, interoperable healthcare platforms. With a team of HIPAA- and FHIR-trained professionals and a track record of delivering 120+ custom healthcare solutions, we help healthcare providers, startups, and health-tech companies accelerate innovation, improve patient care, and simplify operations.
-

Vervelo designs your AI knowledge base and retrieval architecture around your specific clinical workflows, document types, and access control requirements — not a generic RAG template.
-

From single-source RAG to multi-source hybrid retrieval with knowledge graphs — we scope the context engineering stack to match your use case complexity and budget.
-

Context window optimization and semantic caching reduce inference costs by 30–50% on average — making production-grade context engineering a cost reduction, not just a quality investment.

Frequently Asked
Questions
Have a question that needs a human to answer? No problem.
Speak to our team now → What is context engineering and how is it different from prompt engineering?
Prompt engineering is about designing the instructions you give the model. Context engineering is about designing the information you put alongside those instructions — the retrieved knowledge, conversation history, user-specific facts, and structured data the model reasons over. Both matter, but context engineering is the more common source of production AI failures: the model had the wrong information, too much noise, or no relevant history — not because the prompt was badly written, but because the information architecture was poorly designed.
What is RAG and when do you need it?
Retrieval-Augmented Generation (RAG) is the pattern of retrieving relevant information from a knowledge base and injecting it into the model's context window before generating a response. You need RAG whenever your AI system needs to reason over information that is not in the model's training data — your organization's specific protocols, patient records, payer policies, product documentation, or any proprietary knowledge. Without RAG, the model either hallucinates or refuses to answer questions about your specific context.
How do you ensure retrieved content is accurate and relevant?
We measure it. Every retrieval pipeline we build is evaluated against a ground truth dataset using RAGAS metrics — context precision (are the retrieved passages actually relevant?), context recall (are all the relevant passages retrieved?), and faithfulness (does the model's response accurately reflect the retrieved content?). We don't ship retrieval pipelines without benchmark scores, and we monitor these metrics in production so quality degradation is detected automatically.
Can you build context pipelines that work with our EHR system?
Yes — EHR integration is one of our primary specializations. We build FHIR-native ingestion pipelines that pull patient data, clinical notes, lab results, and medication lists from major EHR systems (Epic, Cerner, athenahealth, others via SMART on FHIR). All PHI is handled under HIPAA-compliant protocols with de-identification at ingestion for non-clinical AI contexts and full access control at the retrieval layer for clinical applications.