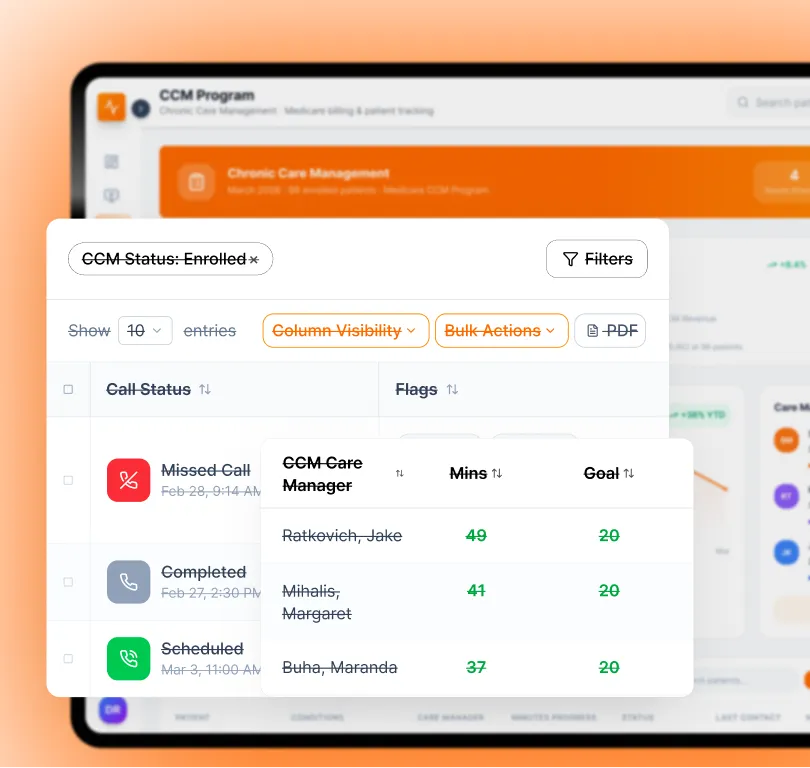
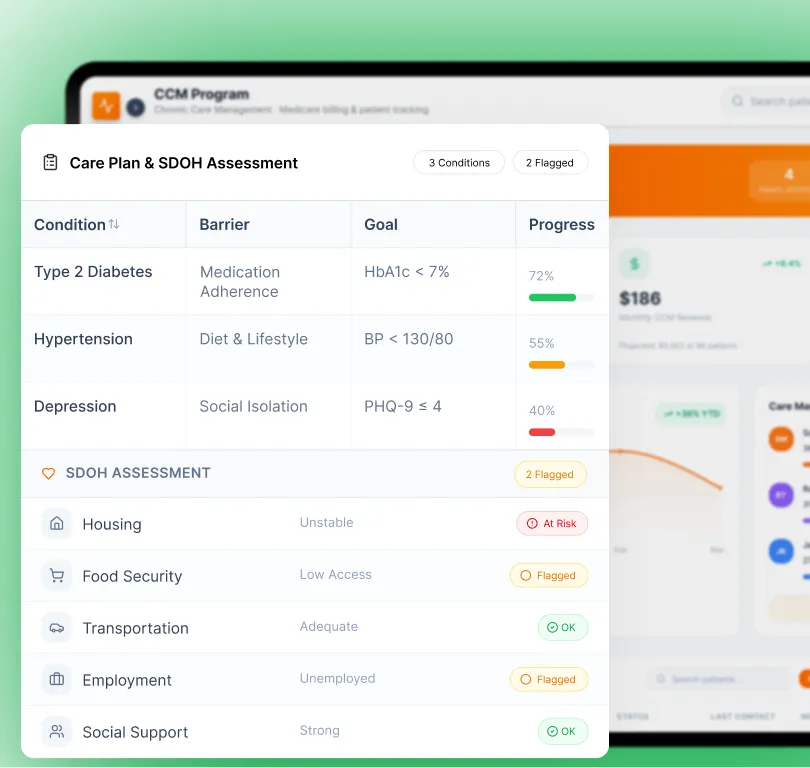
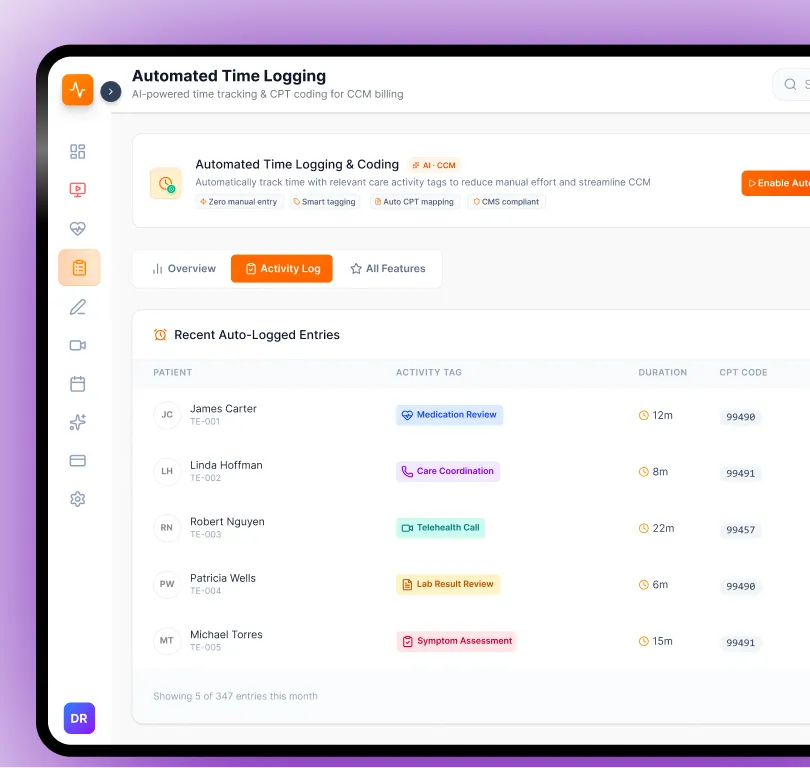
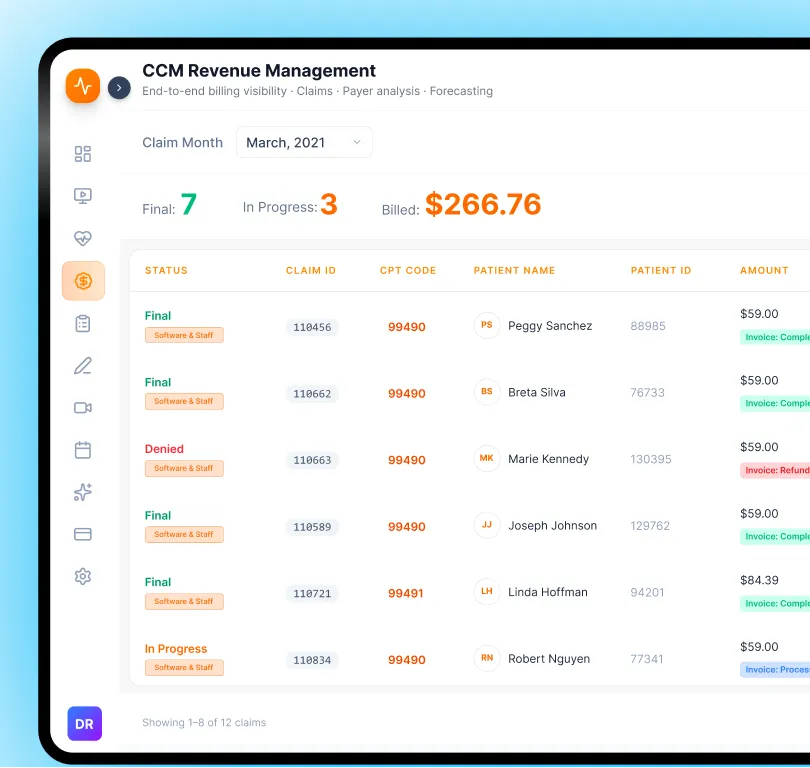
Capability 01
Data Curation
High-quality fine-tuning starts with high-quality data. We build task-specific corpora with robust filtering, normalization, and annotation QA so training data reflects real clinical and operational workflows.
Core Activities
- Data audit covering format consistency, missingness, duplication, and label leakage
- Schema and prompt template design for supervised examples and instruction pairs
- Annotation guideline creation with reviewer calibration and inter-rater quality checks
- Train/validation/test split strategy with time-based and edge-case holdouts
Deliverables
- Versioned dataset with lineage
- Data quality scorecard
- Coverage report by scenario and intent
Expected Outcomes
- Lower hallucination rates
- More stable outputs across edge cases